Nuit Du Hack CTF 2016 Write-Up: Catch me if you can
We managed to infect the computer of a target. We recorded all packets transferred over the USB port, but there is something unusual. We need them to be sorted to get the juicy secret.
The challenge is available at http://static.quals.nuitduhack.com/usb.pcap
Solution
This is a forensics task worth 100pts.
The provided pcap file contains 22 USB packets, as shown in the Wireshark screenshot below
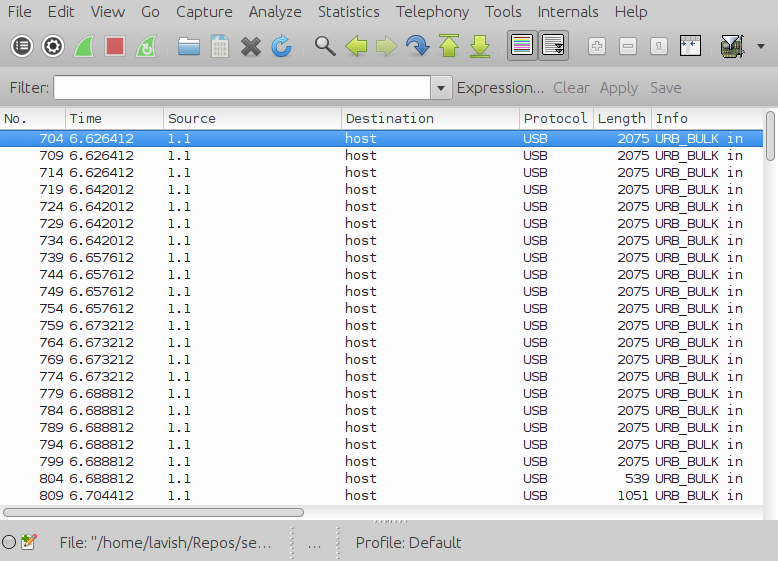
By dumping those packets into the files part01, part02, …, part22, we can see that the first two packets pertain to OpenDocument spreadsheet files
0 $ file parts/part0{1,2}
parts/part01: OpenDocument Spreadsheet
parts/part02: OpenDocument SpreadsheetA rough manual inspection of the dumped parts suggets that the sniffed USB pcap contains only two ODS documents. Moreover, the last two parts are likely to be the last blocks of the ODS files, given that both packets contain the string META-INF/manifest.xml.
To reconstruct the ODS files, we bruteforce all the possible combinations of the dumped parts under the hypotesis that the packets appear ordered with respect to each file in the pcap dump. Working with these assumptions, the number of all the possible packet sequences is 2**19 == 524288. The following Python script explores the whole combination space and for each packet sequence it checks whether the assembled file is a valid zip archive (which is the underlying file format used by ODS). If so, the sequence of the first file is correct and we can dump both files.
#!/usr/bin/python3.5
import io
import sys
import zlib
import zipfile
from itertools import combinations, product
def is_zip(f):
"""Check if the provided file-like object is a valid zip."""
try:
with zipfile.ZipFile(f) as myzip:
res = myzip.testzip()
return res is None
except (zipfile.BadZipFile, ValueError, zlib.error):
pass
return False
def flike_write(flike, fname):
"""Write a file-like object to the fs."""
flike.seek(0)
with open(fname, 'wb') as f:
f.write(flike.read())
def main():
# read all the files parts (parts/part01 .. parts/part22)
parts = [open('parts/part{}'.format(str(n).zfill(2)), 'rb').read() for n in range(1,23)]
# strip the trailing 248 null bytes except for the last two parts
parts = [p[:-248] if i < 20 else p for i, p in enumerate(parts)]
# get the correct sequence of parts for the first ODS file. We try all the
# possible combinations with increasing lengths, assuming that the first
# part is the header of the first ODS, the second part is the header of the
# second ODS and one of the last two parts is the end block of the first file
for n in range(19):
for comb, end in product(combinations(range(2, 20), n), range(20, 22)):
comb_a = [0] + list(comb) + [end]
# join all the parts and check if the result is a valid zip
fdata_a = io.BytesIO(b''.join(parts[i] for i in comb_a))
if is_zip(fdata_a):
# write the first ODS to fs
flike_write(fdata_a, 'result_a.ods')
# construct the second ODS and dump it
comb_b = [x for x in range(22) if x not in comb_a]
fdata_b = io.BytesIO(b''.join(parts[i] for i in comb_b))
flike_write(fdata_b, 'result_b.ods')
print((
'Written result_a.ods and result_b.ods\n'
'Part sequence for result_a.ods: {}\n'
'Part sequence for result_b.ods: {}').format(
comb_a, comb_b))
sys.exit(0)
sys.exit(1)
if __name__ == '__main__':
main()By executing the script we get the two ODS files result_a.ods and result_b.ods
0 $ time ./split.py
Written result_a.ods and result_b.ods
Part sequence for result_a.ods: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
Part sequence for result_b.ods: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21]
real 0m14.893s
user 0m14.880s
sys 0m0.024sThe first ODS does not appear to be relevant to the solution, whilst result_b.ods provides the string g6d5g5f2b6g5d3e in the lower right cell of the spreadsheet. This string is just a sequence of coordinates for the table provided in the same file.
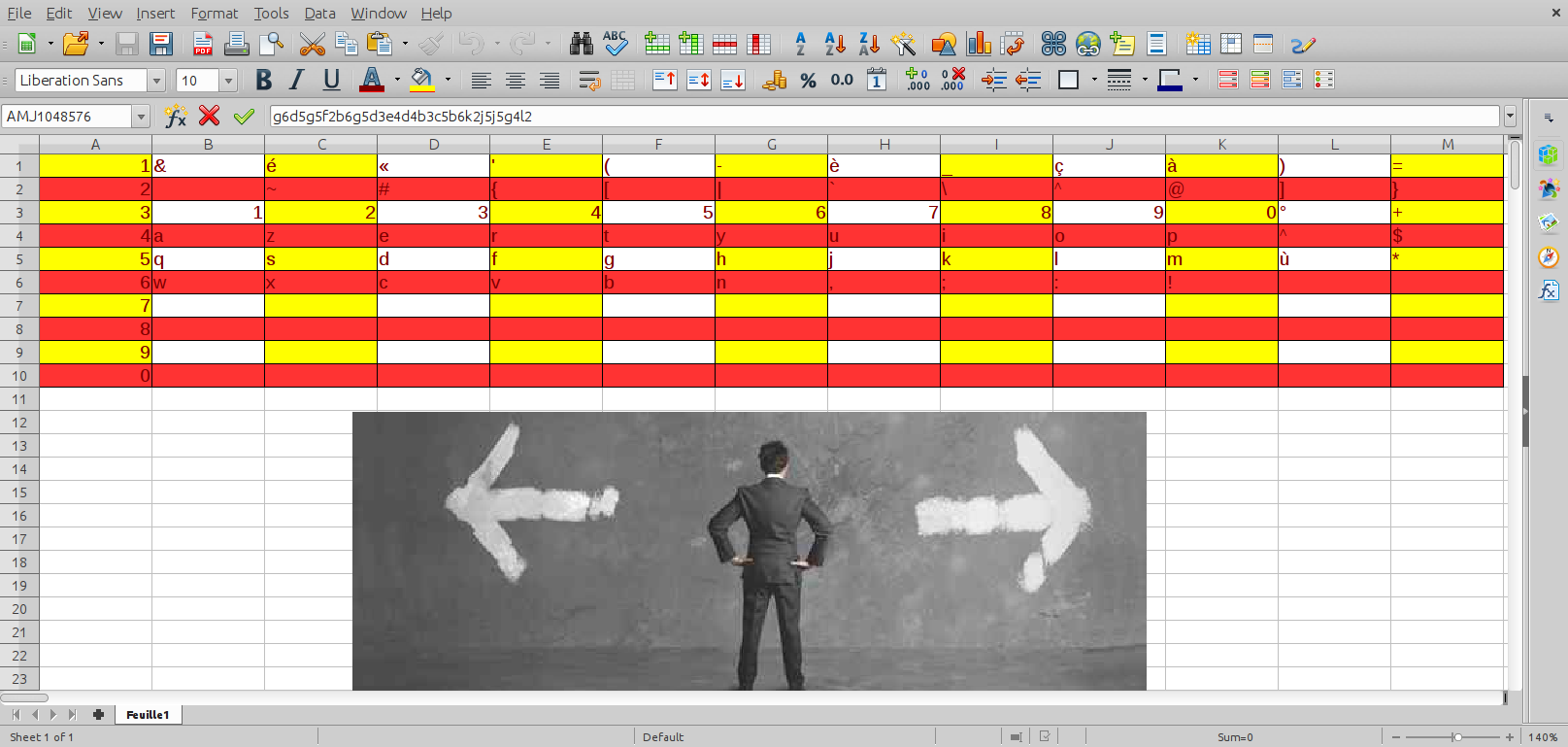
By mapping each coordinate to the correct character we retrieve the flag: ndh[wh3re1sw@lly]