FAUST CTF 2017 Write-Up: Alexa
There’s no way to live in the Internet of Sh…Things without a personal intelligent assistant! Unlike the real one, this version of Alexa is a Django based web app that allows to upload small audio files and provides responses without performing any speech to text processing.
A quick look at the sources reveals that the debugging page http://<ip>:8000/alexa/debug/latest provides hyperlinks to the latest 100 queries. By following the links it is possible to download the audio file uploaded by the bot containing the flags. But how flags are stored within these files? Look at the picture below…
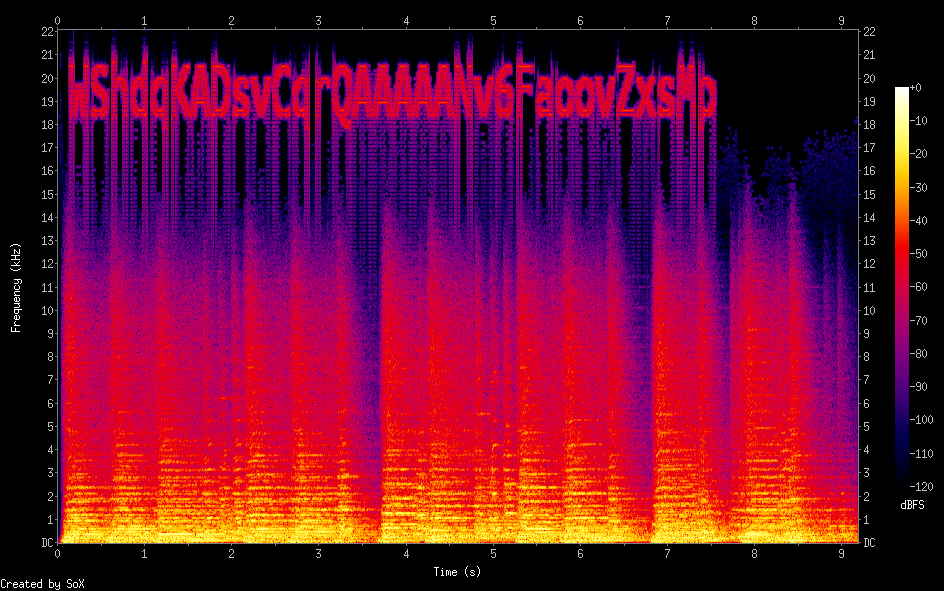
Yes, it’s the spectrogram of the audio sample. We spent hours trying to recognize these flags programmatically using several different OCRs, but none of them could identify the whole text correctly. Eventually, we managed to do it using a simple 1-nn classifier, but couldn’t make it in time for the CTF. We’re not sure this was the intended way to extract flags but it seems to work well, and it’s anyway better than reading and submitting them by hand… :D
We used SoX to plot spectrograms and ImageMagick to extract characters of the flag as single images:
$ sox sample.ogg -n trim 0.10 7.50 sinc 18k spectrogram -o spectr.png -r -x 1000 -Y 400 -Z 100 -z 180 -l -h
$ convert spectr.png -crop 992x60+4 +repage -white-threshold 90% -depth 4 +dither -colors 2 better-spectr.png
$ convert -crop 31x60 better-spectr.png chars/%d.png
$ ls chars/
0.png 11.png 14.png 17.png 2.png 22.png 25.png 28.png 30.png 5.png 8.png
1.png 12.png 15.png 18.png 20.png 23.png 26.png 29.png 31.png 6.png 9.png
10.png 13.png 16.png 19.png 21.png 24.png 27.png 3.png 4.png 7.png
The parameters used are just fruit of repeated trials and adjustments, and lead to images like:

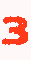


The training set for the classifier can be built in some minutes by collecting and manually labeling two or three images for each character of the flag format. Since the CTF was already over, we tested the trained classifier only on 10 random audio samples, on which it obtained 100% accuracy and allowed to successfully retrieve the 10 flags.
PoC
Contents of train.py:
#!/usr/bin/env python3
import os
import pickle
import numpy as np
import scipy.misc
import sklearn.neighbors
def load_training_set():
X, Y = [], []
for filename in os.listdir('training-chars'):
if filename.endswith('.png'):
im = scipy.misc.imread(os.path.join('training-chars', filename), mode='L')
im = im.flatten()
X.append(im)
Y.append(filename[0]) # first character of the filename is the label
return np.asarray(X), np.asarray(Y)
X, Y = load_training_set()
inv_I, I = np.unique(Y, return_inverse=True)
clf = sklearn.neighbors.KNeighborsClassifier(1)
clf.fit(X, I)
with open('knn.pkl', 'wb') as f:
pickle.dump([clf, inv_I], f)
Contents of split.py:
#!/usr/bin/env python3
import argparse
import os
import shutil
parser = argparse.ArgumentParser()
parser.add_argument('infile')
args = parser.parse_args()
try:
shutil.rmtree('chars')
except FileNotFoundError: pass
os.makedirs('chars')
infile_without_ext = os.path.splitext(os.path.basename(args.infile))[0]
spectrogram_filename = '{}.png'.format(infile_without_ext)
# create spectrogram
os.system('''\
sox {} -n trim 0.10 7.50 sinc 18k spectrogram -o {} -r -x 1000 -Y 400 -Z 100 -z 180 -l -h
'''.format(args.infile, spectrogram_filename))
# beautify spectrogram
os.system('''\
convert {0} -crop 992x60+4 +repage {0}
'''.format(spectrogram_filename))
os.system('''\
convert {0} -white-threshold 90% -depth 4 +dither -colors 2 {0}
'''.format(spectrogram_filename))
# crop characters
os.system('''\
convert -crop 31x60 {} {}
'''.format(spectrogram_filename, os.path.join('chars', '%d.png')))
Contents of classify.py:
#!/usr/bin/env python3
import os
import pickle
import scipy
with open('knn.pkl', 'rb') as f:
clf, inv_I = pickle.load(f)
chars = [None] * 32
for filename in os.listdir('chars'):
if filename.endswith('.png'):
im = scipy.misc.imread(os.path.join('chars', filename), mode='L')
im = im.flatten().reshape(1, -1)
i = clf.predict(im)[0]
n = int(os.path.splitext(os.path.basename(filename))[0])
chars[n] = inv_I[i]
flag = ''.join(chars).replace('-', '/')
print('The flag is:', flag)
Usage:
$ # train the classifier using labeled examples
$ ./train.py
$ # pick an audio sample and extract the characters from its spectrogram
$ ./split.py test-oggs/WShDpKADCyxzZQAAAABn0aLqqXMrGKGz.ogg
$ # classify each extracted character and recompose the flag
$ ./classify.py
The flag is: WShDpKADCyxzZQAAAABn0aLqqXMrGKGz
Training set, test set and the above scripts are avaiable here.